
国会図書館のWebサイトで、画像からテキストを抽出するOCRソフトがダウンロードできるようになったと言うので、さっそく試してみました。文字の認識力は高く、なかなか使えそうです。
そもそも「NDLOCR-Lite」とは?
まず「OCR(光学文字認識)」とは、紙の書類、PDF、画像データ内に含まれる文字をスキャナーやカメラで読み取り、デジタルテキストに変換する技術です。
国立国会図書館はこれまで「NDLOCR」というOCRソフトを提供していましたが、これにはNVIDIAのGPU(グラフィックカード)が必要でした。しかし、今回リリースされた「NDLOCR-Lite」はGPU要件がなくなり、一般的なPCでも利用することができます。対象となるOSは、Windows 11、macOS 15、Ubuntu 22.04で動作確認済みとのことです。
ここではWindows 11に「NDLOCR-Lite」をダウンロードして、実際にOCRの品質テストを行うところまでを紹介します。
「NDLOCR-Lite」のダウンロード
「NDLOCR-Lite」のダウンロード先: https://github.com/ndl-lab/ndlocr-lite/releases
このページを少しスクロールすると以下のような欄があるので、ファイル名に「windows.zip」とあるものをクリックし、適当な場所にダウンロードしてください。※v1.1.0の部分はその時のバージョンですので変更されることがあります。
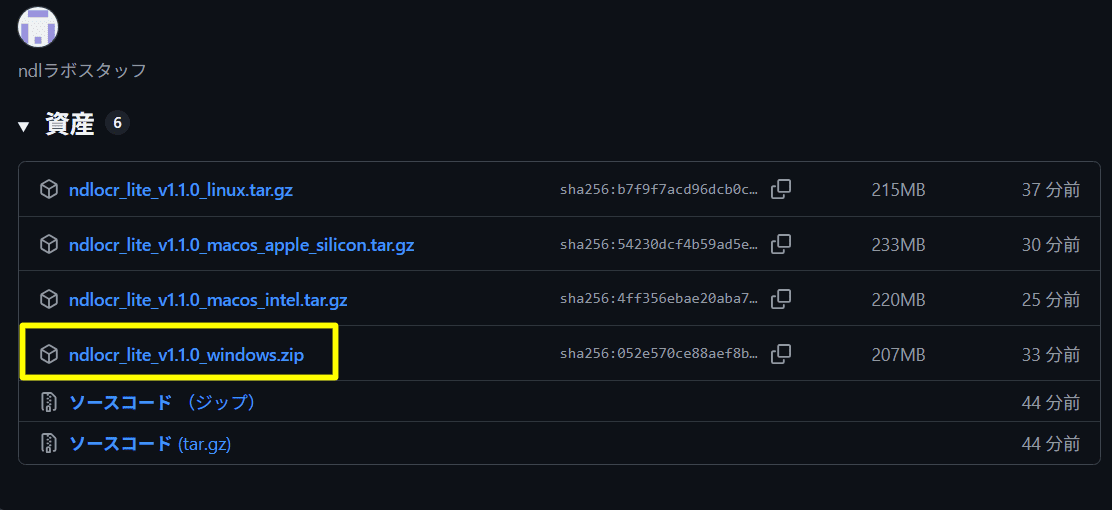
ダウンロードが完了したら、ZIP圧縮されたフォルダを右クリックし、メニューから「すべて展開」をクリックするとファイルが解凍(展開)されます。
「NDLOCR-Lite」はPCにインストールするわけではないので、準備はこれで終了です。次はスキャンした画像データから文字起こしをしてみましょう。
今回試した画像ファイルは、岩波文庫『ギリシア哲学者列伝(下)』のP298-299をサンプルとして利用させていただきました。

スキャナで読み込んだページを画像ファイルで保存したら、解凍した「NDLOCR-Lite」フォルダを開き、「ndlocr_lite_gui.exe」をダブルクリックで実行します。
この時、Windowsが警告を出してくると思いますが、そのまま「詳細情報」をクリックします。
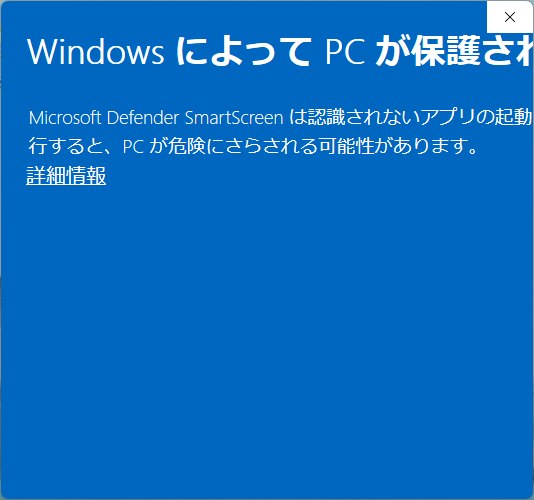
下部の横スクロールバーで少し右にずらし「実行」ボタンをクリックします。

すると、以下のような画面が開きます。※下図はすでにスキャンデータを読み込んだ状態です。

基本的な指定か所は、上図の3つです。
画像ファイルを1枚ずつ処理するなら「画像ファイルを処理する」。複数の画像をまとめて処理する場合は「フォルダ内の画像を処理する」を選択します。
「出力先を選択する」で、読み取った文字データを保存する場所を指定します。
「OCR」ボタンは、その画像全体に含まれる文字をテキスト化。「Crop&OCR」は、画像の中を範囲選択して、その中に含まれる文字をテキスト化します。
さて、無事にちゃんとテキストデータが抽出されたか見てみましょう。
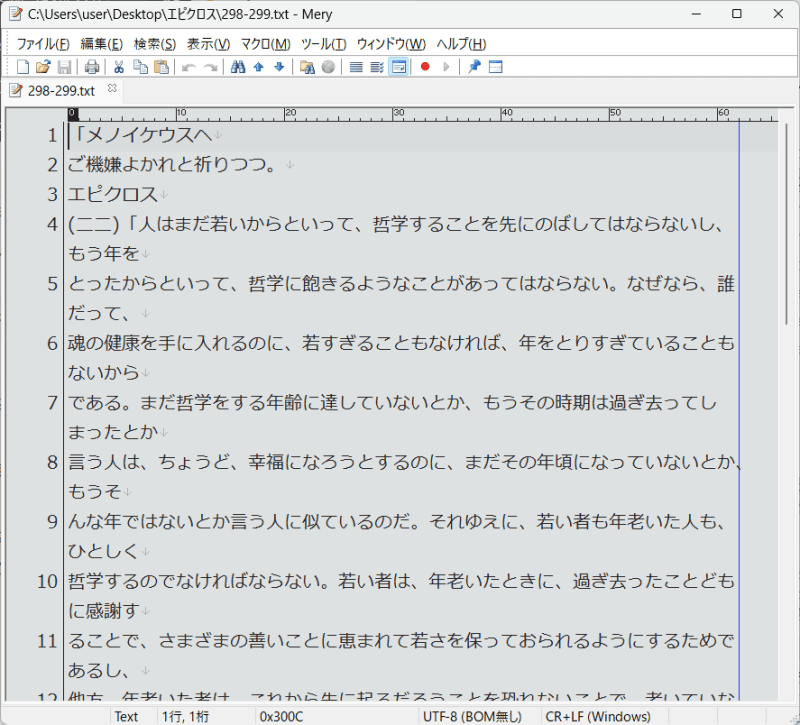
ほぼバッチリですね。4行目の(二二)は、ほんとうは(一二二)なんですが。あとは改行を手直しするだけで良さそうです。
出力形式は、
- テキスト形式
- JSON形式
- XML形式
- TEI(Text Encoding Initiative)に準拠したテキストデータのTEI形式
- PDFにテキストデータを透明テキストとして埋め込んだ透明テキスト付PDF形式
が選択できます。
画面上の文字もデータ化できる「キャプチャモード」を試してみる
「NDLOCR-Lite」はパソコン画面に表示されているWebサイト等のテキストをOCRすることもできます。今度は、当サイトのページをキャプチャしてみましょう。
「NDLOCR-Lite」を起動したら、「キャプチャモード」をクリック。
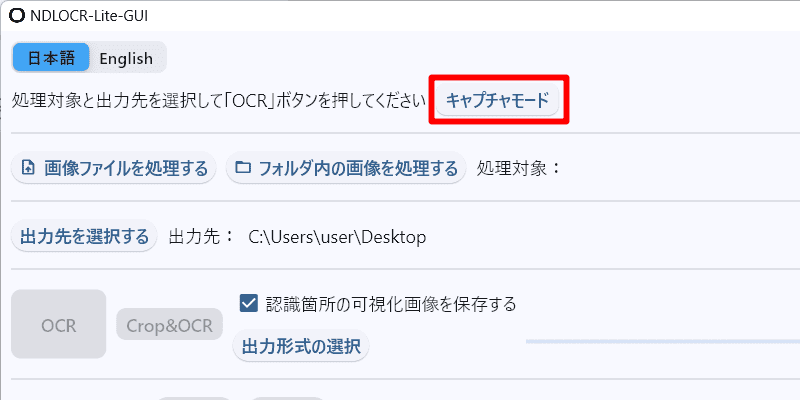
「NDLOCR-Lite」が透明になるので、画面上でマウスをドラッグし、テキスト化したい部分を範囲選択します。

「キャプチャ結果」画面をチェックして、これで良ければ下部の「OCR実行」をクリック。
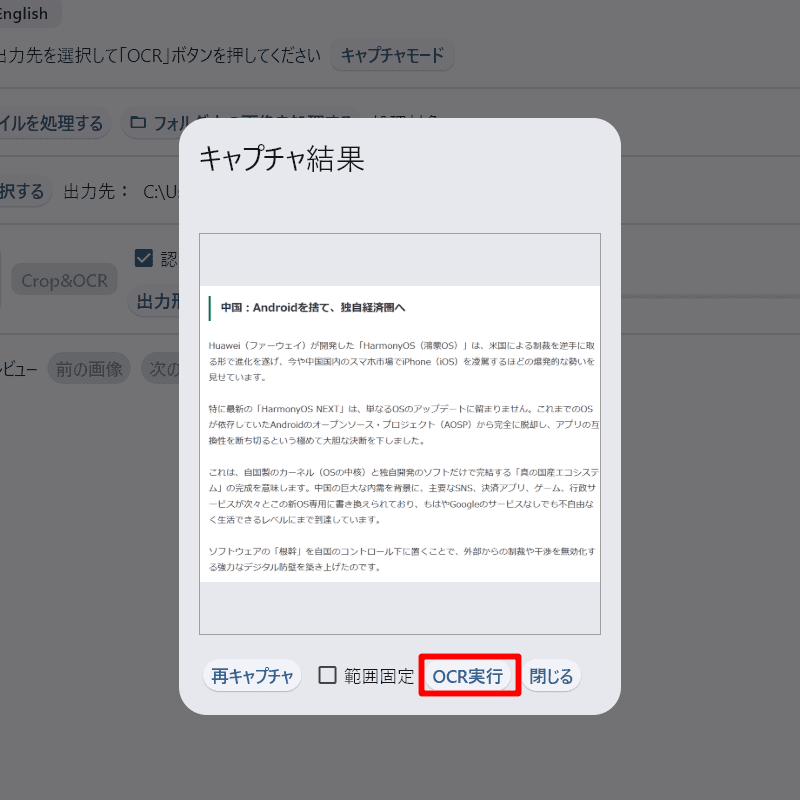
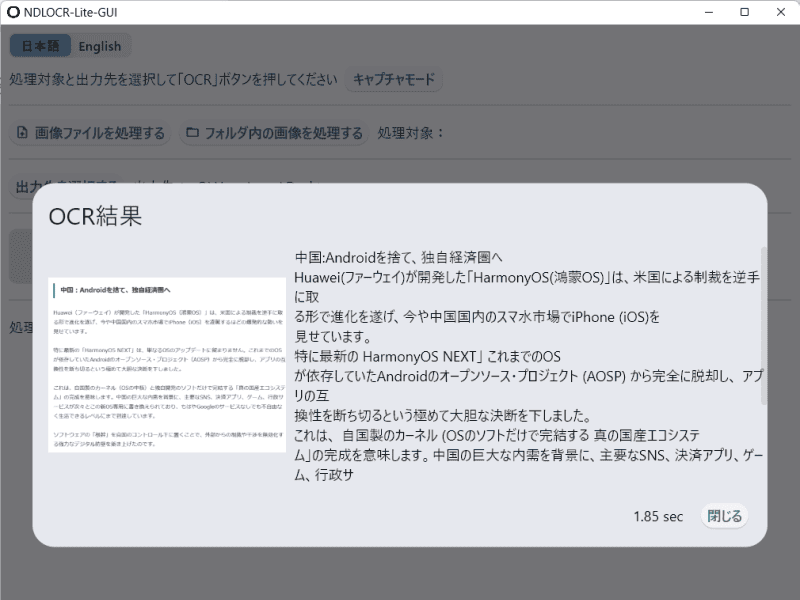
実行すると下のような画面が出るので、テキストを選択し、メモ帳などに貼り付けてください。
結論:「NDLOCR-Lite」は無料でも、かなり使える!
いかがでしたでしょうか?
試してみた結果、テキストの認識率はなかなか高いと思いました。しかも、「NDLOCR-Lite」はPCにインストールするアプリではないので、USBメモリに入れて出先のPCでも作業できそうなのがいいですね。
なお、Macユーザーの方向けには、NDL古典籍OCR-Lite(ndlkotenocr-lite)をMac OSで使用する というサイトが参考になります。

